FoundationModels: Basic Prompting for an iOS Reader App
The app is open-sourced ↗
The article was updated for Xcode 26 Beta 5
Since I’ve heard about the new Swift APIs to access Apple’s on-device LLM, I wanted to test-drive it on a real project.
Incidentally, I also wanted to build a simple offline reading app. I even had a working prototype already, albeit without any AI features.
So I just went ahead and started building the reading app with AI features in mind, from scratch, using iOS 26 APIs.
In the end, I had a working reader app with offline support, as well as AI-based summaries and Q&A.
Offline Reading
I don’t want to spend much time covering non-AI stuff here.
The core features are pretty basic: you can add articles to the app. Once added, you can read any article, even when you’re offline. There is a reader mode, which strips the styling and removes the unnecessary elements, similar to Safari’s Reader feature. Once you’ve read the article, you can archive it. That’s it.
To render and persist webpages, I’ve used the latest WebKit APIs for SwiftUI. As with many SwiftUI additions, I’ve found the new WebKit APIs to be ergonomic, yet slow and unreliable.
To render the page, I’ve used WebView. To get the page data, I’ve used the WebPage.load() function:
@State private var page = WebPage()
page.load(URLRequest(url: url))To persist the content for offline use, I’ve used SwiftData to store the article’s data, including both the reader mode HTML and the raw article’s text:
// Store first
article.pageData = try? await page.exported(as: .webArchive)
// Load later
page.load(article.pageData, mimeType: "text/html", characterEncoding: .utf8, baseURL: url)Data Processing
To convert the page’s HTML for a reader mode, I’ve used Reeeed ↗:
let result = try await Reeeed.fetchAndExtractContent(fromURL: url)
let html = result.html(includeExitReaderButton: false)Reeeed also conveniently exposes a function to get plain text, stripped of all HTML. This would be handy for our AI features.
let result = try await Reeeed.fetchAndExtractContent(fromURL: url)
let content = result.extracted.extractPlainText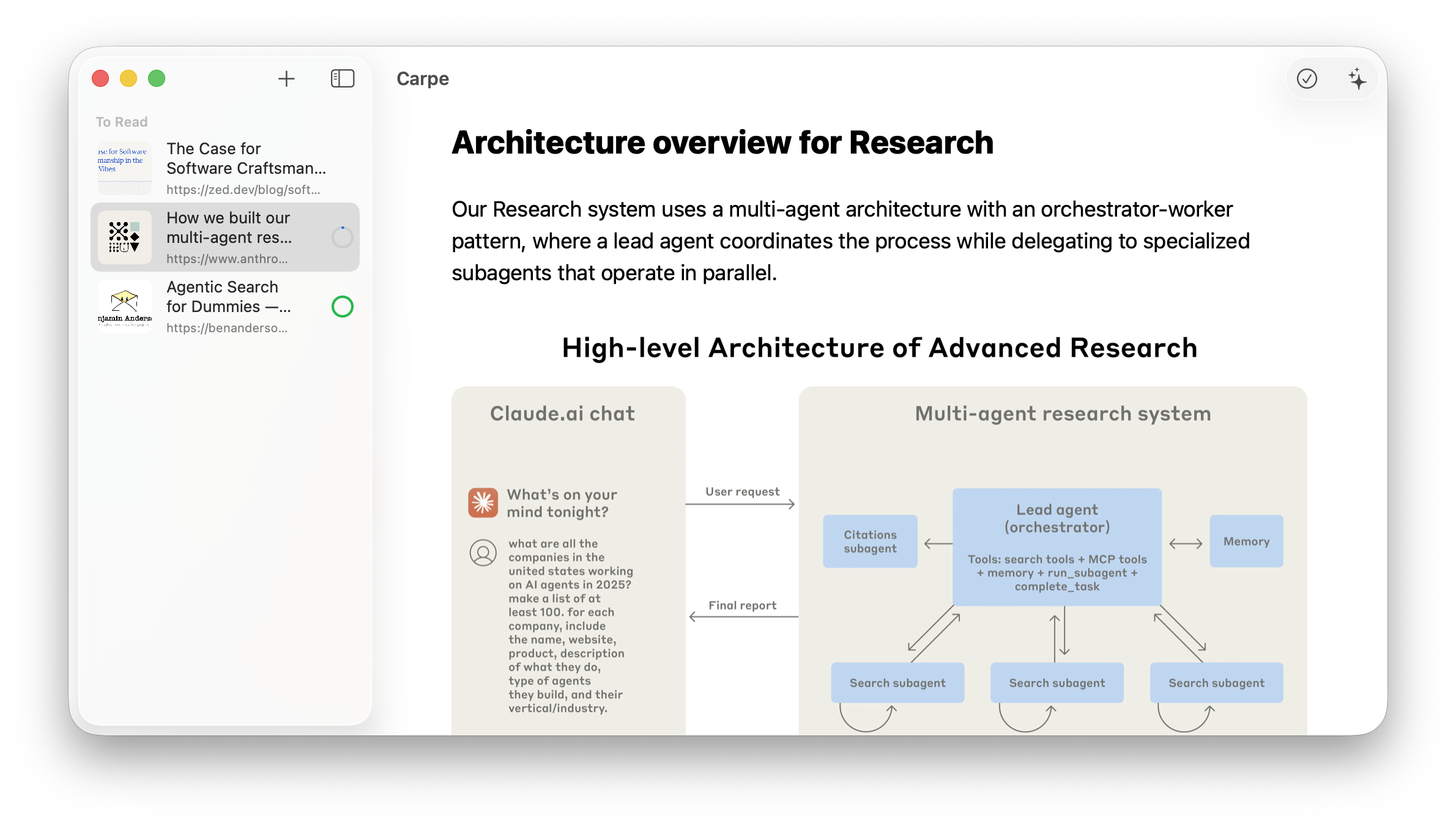
Summarization
Now we have everything to implement the AI side of things. We will start by getting the summaries.
I’ve started with a simple prompt:
Summarize this article in 1-3 paragraphs. Focus on the main points and key insights.I found the results to be quite good. While the summaries do sound very LLMish, they convey the meaning decently.
The problem is that it wouldn’t cut it for any long enough text. The model’s context window is 4096 tokens in total, which is roughly 20 thousand characters. Safely, we can put around 15 thousand characters there. Why not 20 thousand? Two reasons: we need to fit the output as well and we need some wiggle room, as the character to token ratio is not constant.
This is enough to fit small notes or even medium-sized articles, but not nearly enough to handle long reads and deep dives.
The simplest solution would be to trim the article down to the first ~15 thousand characters. A slightly smarter solution would be to pick the 15k chars in the middle, to jump straight into the article’s “meat”.
Obviously, that will work worse and worse as the article gets longer. A much better solution is to implement chunking.
The algorithm is simple. If the article is short enough to fit into the context, we process it as-is, with the prompt above. If it’s longer, we chunk it, process each chunk separately, then synthesize the final summary, taking the summaries of each chunk as input.
private static func generateChunkedSummary(from content: String) async throws -> String {
let chunks = content.chunked(into: CHUNK_SIZE)
var chunkSummaries: [String] = []
// Process chunks sequentially to avoid overwhelming the device
for (index, chunk) in chunks.enumerated() {
let session = LanguageModelSession {
"Summarize this section of an article (part \(index + 1) of \(chunks.count)) in 1-2 short paragraphs. Focus on the key points:"
}
let response = try await session.respond(options: .init(maximumResponseTokens: 500)) {
chunk
}
chunkSummaries.append(response.content)
}
// Generate meta-summary from chunk summaries
let combinedSummaries = chunkSummaries.joined(separator: "\n\n")
let metaSession = LanguageModelSession {
"These are summaries of different sections of a long article. Create a cohesive summary in 2 - 4 paragraphs that captures the overall main points and key insights:"
}
let metaResponse = try await metaSession.respond(options: .init(maximumResponseTokens: 1_000)) {
combinedSummaries
}
return metaResponse.content
}Make sure to run the LLM sessions sequentially, as running multiple requests can result in an error.
Use
maximumResponseTokensto control the model’s output size. This is especially helpful when working with larger contexts.
The above will work for most articles. There are limits to this technique, where you’d need to add another meta layer for very large articles, but in practice, you almost never run into that.
While testing the summarization features, I’ve noticed that the summary size is always the same. No matter the article size, it would always give me a 3-paragraph summary of roughly the same length.
I decided to guide the model a bit by setting the paragraph count range based on the input size.
private static func generate(from content: String) async throws -> String {
let params = getSummaryParams(content: content)
let session = LanguageModelSession {
"Summarize this article in \(params.paragraphsMin)-\(params.paragraphsMax) paragraphs. Focus on the main points and key insights."
}
}
/// Dynamic summary shape based on the content's size
private static func getSummaryParams(content: String) -> SummaryParams {
switch content.count {
case 0..<10_000:
SummaryParams(1, 1)
case 10_000..<20_000:
SummaryParams(1, 2)
case 20_000..<40_000:
SummaryParams(2, 3)
case 40_000..<60_000:
SummaryParams(2, 4)
default:
SummaryParams(3, 5)
}
}In general, with small, non-reasoning LLMs, you need to guide them as much as possible with the prompt.
You can guide the model’s output dynamically based on the input by parametrizing the prompt.
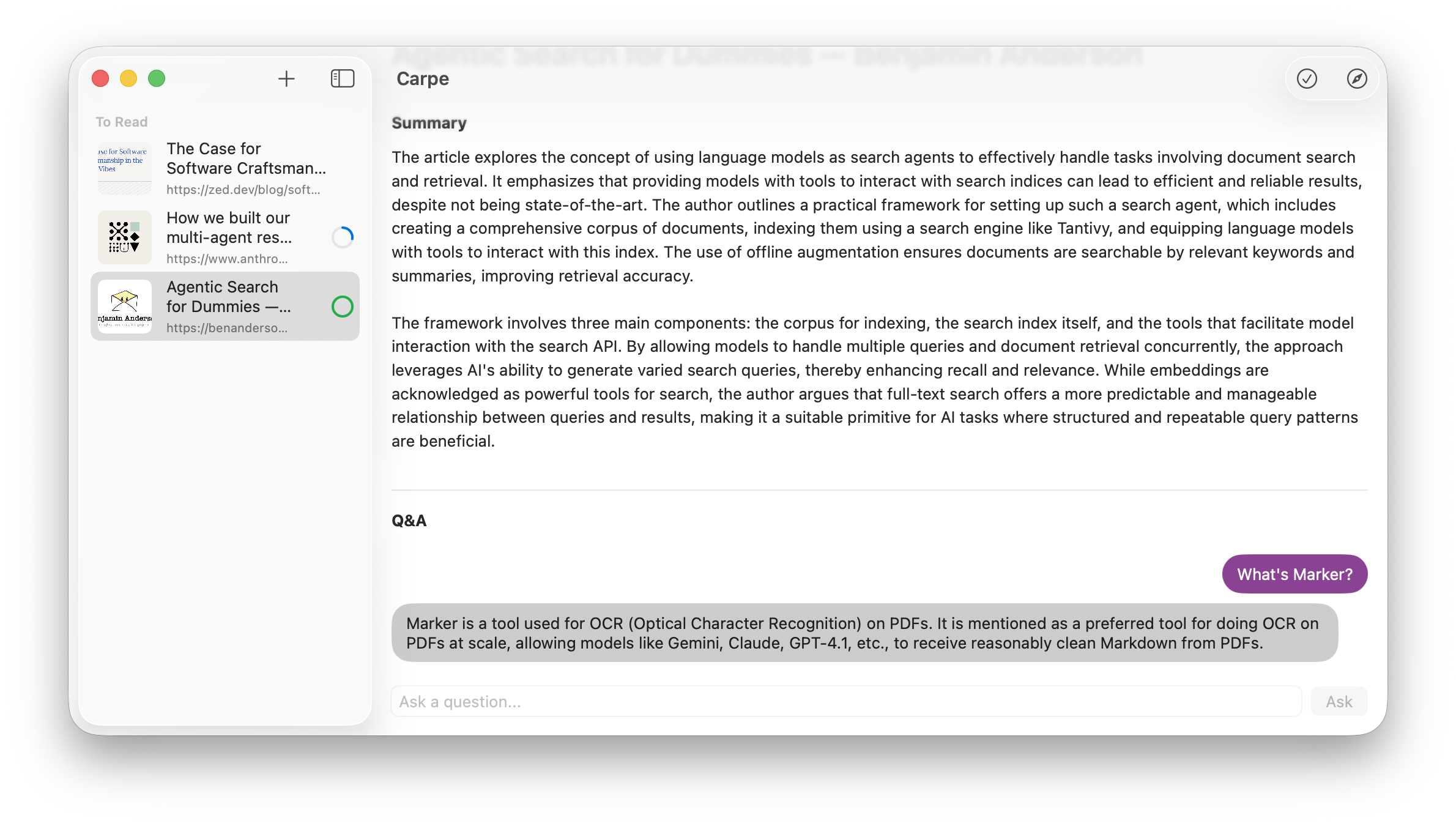
Extraction (Q&A)
Now, let’s move on to the question answering. Again, a simple prompt works well:
Based on the following article content, answer the user's question. Be concise and accurate. If the answer cannot be found in the content, say so clearly.To handle large input, let’s use chunking again. We will look for an answer in each chunk, then aggregate all responses to give the final answer.
Based on my tests, the LLM was able to provide the answer most of the time, although it missed a few shots.
When being asked about something that’s not included in the text, the LLM would say so.
To reduce hallucinations during extraction, give a model a way out
The biggest downside is speed. The LLM takes a few seconds to respond, which increases with the page size. We could implement output streaming to improve the UX, but that’s only effective if the streaming starts instantly. A better approach might be to show the progress indicator, as the number of steps (chunks) is known beforehand.
Troubleshooting
When working on the app, I ran into multiple issues.
Faulty language detection
For some pages, the response generation was denied due to unsupported language. In my case, the language was detected as tr for an article in English. Stripping the HTML tags fixed the issue.
Small context size
Exceeding the content size reverts the generation. Chunking the input content, as well as limiting the output size, solves this.
Performance
LLM inference is slow, especially on low-end devices.
For the summary, I was running the token generation in the background to hide that slowness from the user. I also persisted the outputs, so that the summary is generated only once for each article.
For the Q&A feature, I could implement a progress indicator or streaming.
Model availability
Old devices don’t support Apple Intelligence. Also, running Foundation Models requires iOS 26. We need to handle the environments that don’t support it.
In my case, since all the AI features are located on a separate tab/pane, simply removing that pane from navigation is arguably the best solution. No need for “this device is not supported” screens, as those are generally not actionable and frustrating.
Conclusion
While the reader app itself is pretty useful, I don’t think the AI features are very valuable and something that I’d use a lot.
Summarization and extraction are helpful if you don’t want to go through the entire thing, and just want a quick answer. With the reading app, usually the opposite is true: the article list is curated by you, so everything there is worth your full attention. Going through the summary would just waste your time.
Still, I found it a great opportunity to get started with Apple’s framework and learned a thing or two in the process.