Apple Foundation Model on device
Since iOS/macOS 26, developers can utilize a built-in language model provided by Apple in their apps, using Swift APIs.
This is the same model that powers Apple Intelligence. It is local and private.
Here, I explore the model’s features, capabilities, and benchmarks to provide a high-level overview. For a deep-dive, see the Apple Intelligence Foundation Language Models ↗ by Apple and the 2025 update ↗ from the Apple ML team.
Following best practices, Apple did a terrible job naming its own models. The best nomenclature I could find is AFM-on-device and AFM-server for the local and server Apple models respectively. There seems to be no versioning schema.
Note: here, I’m mostly interested in the on-device model. The server model doesn’t have much public info and is not that interesting overall (there are better models).
Key
- 3 billion parameters
- 2 bits/weight quantization
- context size: 4096 tokens ↗ (input + output)
The model is proprietary and closed-weight.
Most likely, the same model is used across all Apple devices and is part of the software updates (i.e., newer versions of iOS/macOS, including point versions, will get newer/updated models).
Capabilities
- tool calling
- structured outputs
- supports 15 languages
- lightweight, task-specific fine-tuning
No multimodality: Both the text and image models are single-modal.
No reasoning: For advanced reasoning, Apple suggests using large reasoning models.
As of iOS 26 Beta, the image model is not available.
Model Dimensions
| Param | Value |
|---|---|
| Model dimension | 3072 |
| Head dimension | 128 |
| Num query heads | 24 |
| Num key/value heads | 8 |
| Num layers | 26 |
| Num non-embedding params (B) | 2.58 |
| Num embedding params (B) | 0.15 |
Training data
As per paper ↗, Apple used:
- data licensed from publishers
- publicly available curated datasets
- open-sourced datasets
- open source repositories on GitHub
- information crawled by Applebot, Apple’s web crawler
No personal data from Apple users was used.
The model was trained from scratch (i.e., it’s not based on any existing open-source model).
Benchmarks
Pre-training
AFM On-Device vs external models on representative benchmarks:
| Model | MMLU | MMMLU | MGSM |
|---|---|---|---|
| AFM On-Device | 67.85 | 60.60 | 74.91 |
| Qwen-2.5-3B | 66.37 | 56.53 | 64.80 |
| Qwen-3-4B | 75.10 | 66.52 | 82.97 |
| Gemma-3-4B | 62.81 | 56.71 | 74.74 |
| Gemma-3n-E4B | 57.84 | 50.93 | 77.77 |
AFM Server vs external models on representative benchmarks:
| Model | MMLU | MMMLU | MGSM |
|---|---|---|---|
| AFM Server | 80.20 | 74.60 | 87.09 |
| LLaMA 4 Scout | 84.88 | 80.24 | 90.34 |
| Qwen-3-235B | 87.52 | 82.95 | 92.00 |
| GPT-4o | 85.70 | 84.00 | 90.30 |
Representative metrics on quality impact through optimization:
| Model | MMLU | IFEval (instruct) | Bits-per-weight |
|---|---|---|---|
| AFM On-Device | 67.8 | 85.1 | 16 |
| AFM On-Device Opt | 64.4 | 82.3 | 2 |
| AFM Server | 80.0 | 89.1 | 16 |
| AFM Server Opt | 79.2 | 90.2 | 3.6 |
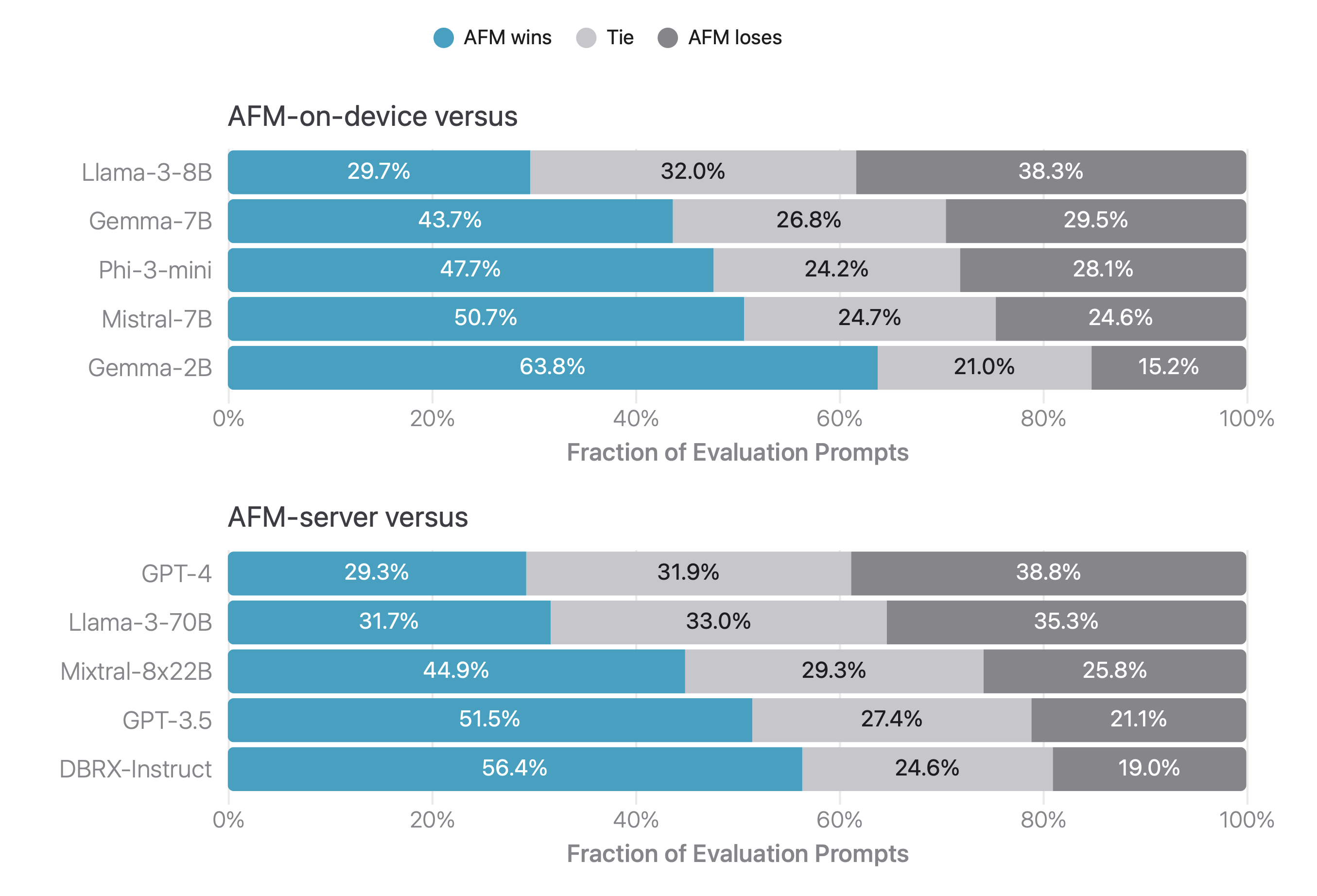
Human Evaluation
Instruction Following

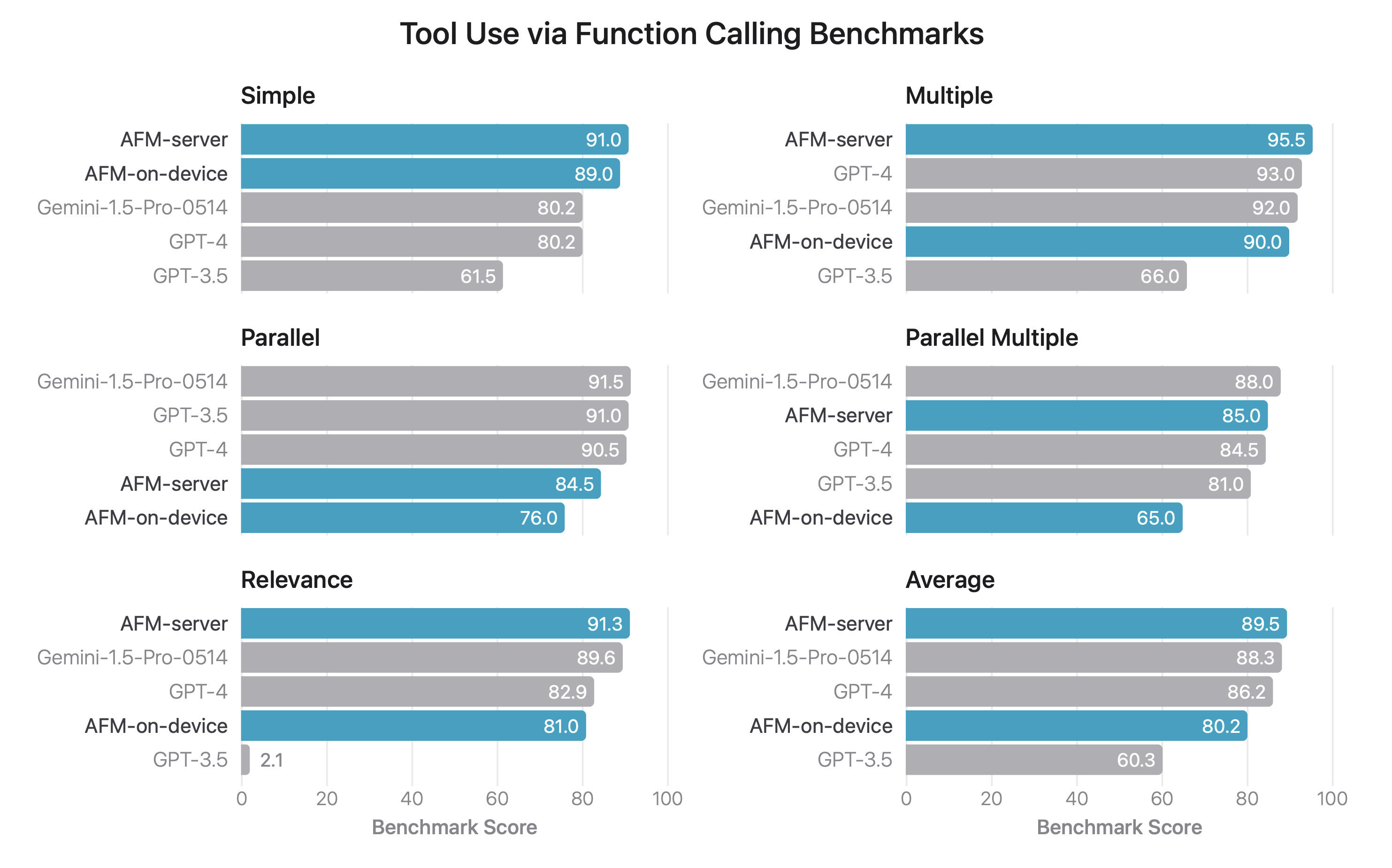
Tool Use
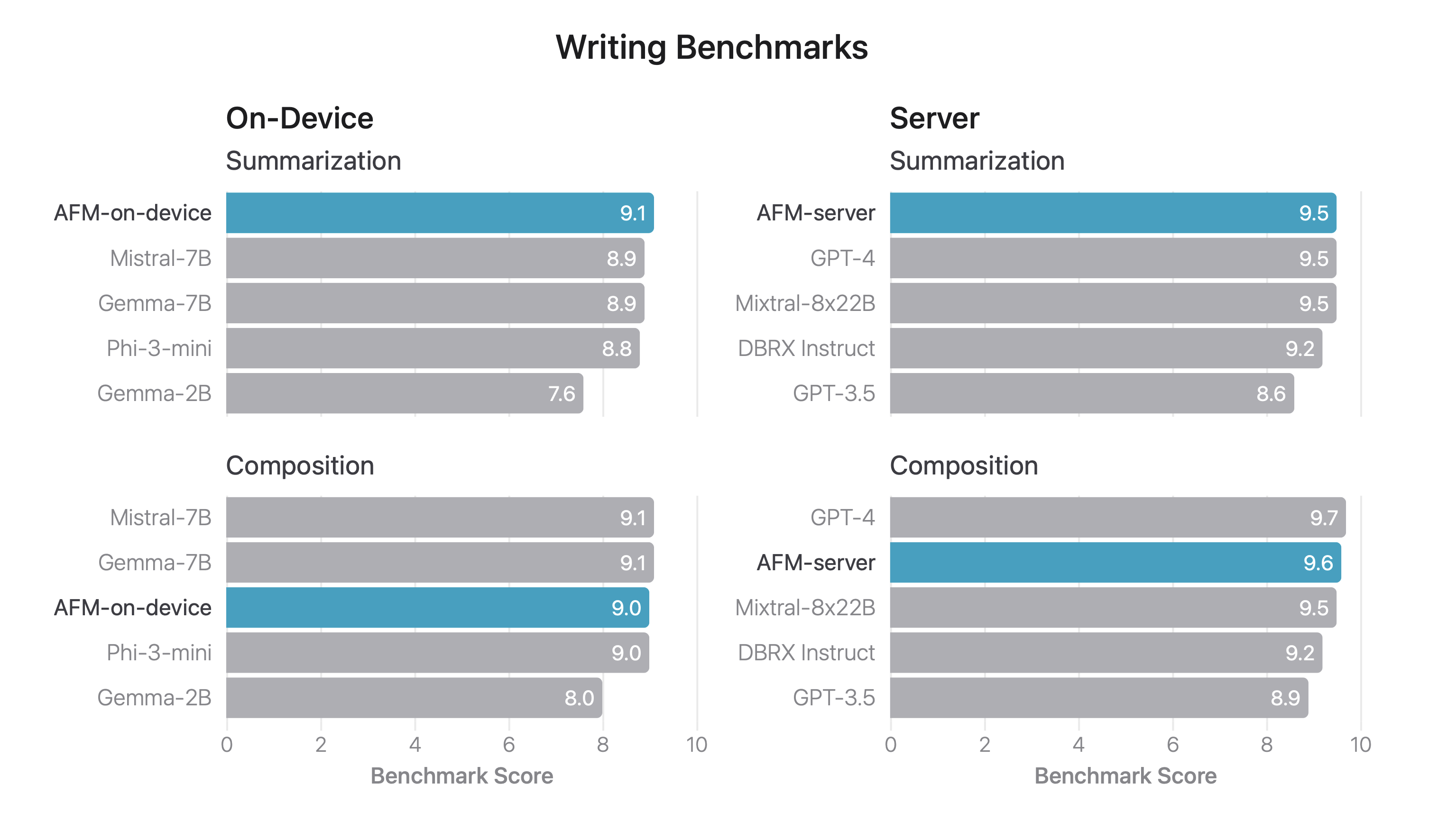
Writing
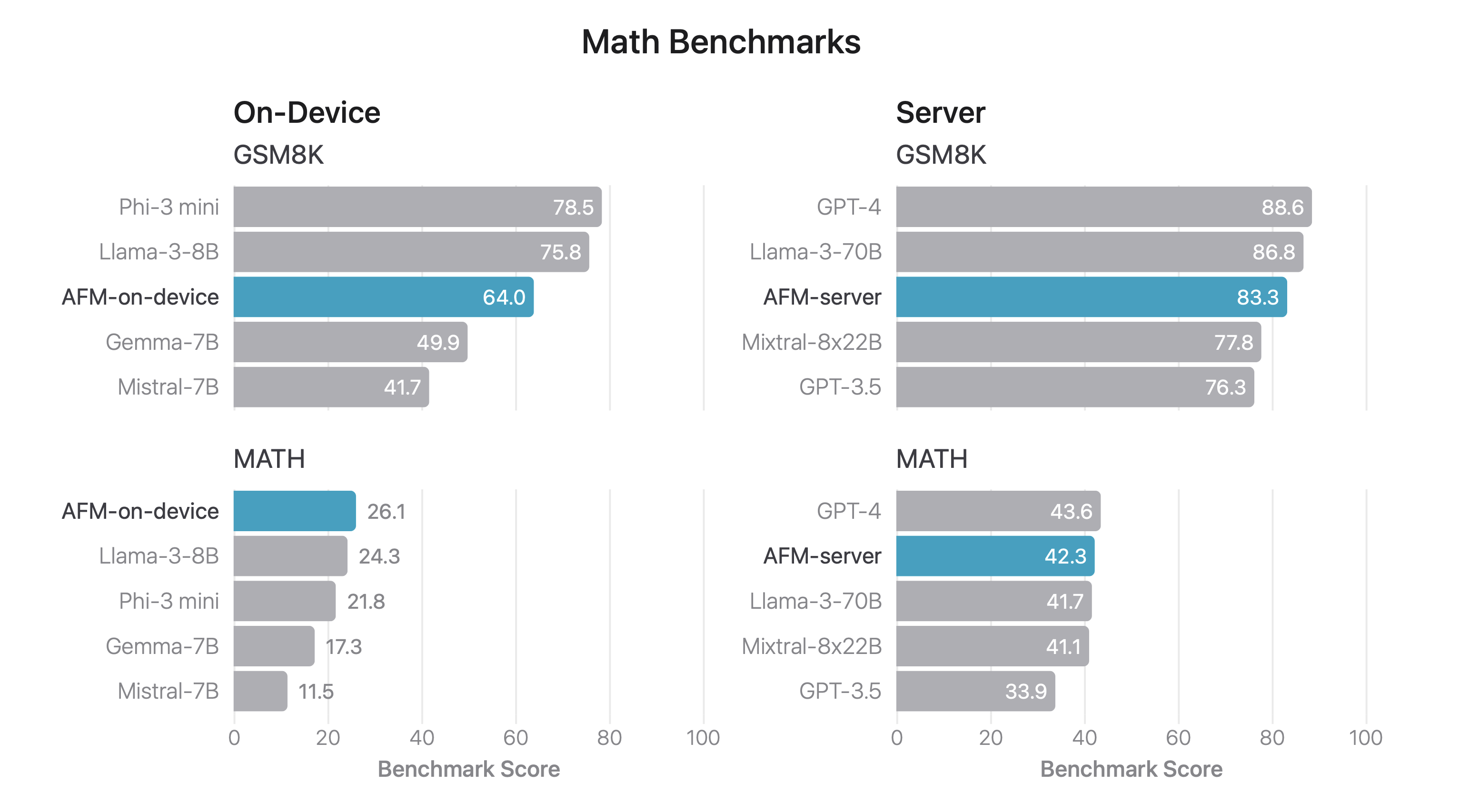
Math
Safety
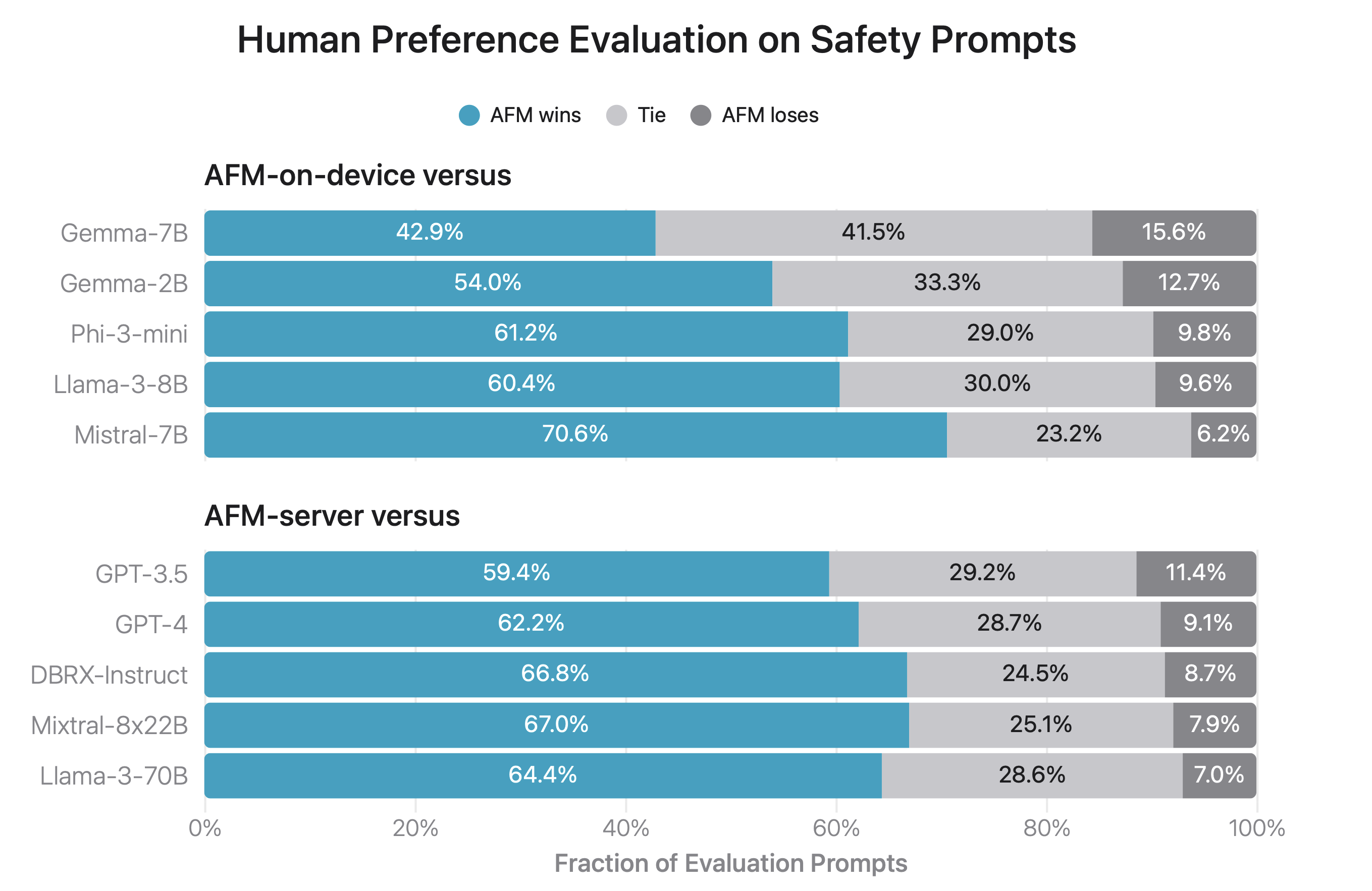
Conclusion
Overall, the model seems to be on par with small open-source models.
On iPhone (and likely iPad), it now makes no sense to bring any third-party models (as installing and managing those will net worse UX).
On macOS, I’d expect to have the option to run third-party on-device and hosted models (especially for pro users and complex use cases), while using AFM by default.